Introduction to Neural Networks and Machine Learning
In the Modern era, Everything is getting automated and usage of machines has increased a lot from past 4–5 years. It is much useful to make machines learn and perform tasks within seconds as humans need long hours to make them done. Neural Networks which mimic the human brain is helpful in doing certain tasks. Come, let’s know about it.
Neural Network is a system designed to mimic the human brain and make decisions. Here among all the layers of a network and output layer makes predictions after going through a humongous amount of calculations. It is a computational model that has a network architecture. This architecture is made up of artificial neurons. This structure has specific parameters through which one can modify it for performing certain tasks.

Humans learn quickly, make it slow. Machines learn slow but make it fast. As we have a humongous amount of work to be done even if learning is slow we prefer making it quicker. That is the reason we prefer machines to work on it. For a machine to do all those things first of all we need to train it on that type of data. The process of making machines learn the work which needs to be done is known as Machine Learning.

For example, Consider a case we need to separate dogs and cats from a huge data mixture of cats and dogs (this example is taken as it is a most considered problem to classify dogs and cats) we have to train it with all different types of dogs and cats existed. So that it learn all the patterns based on the trained data and when it is performing(predicting) it gives prediction with better accuracy.

There are many things to be taken into account while training a model, starting with which selection of framework, Architecture,hyper parameters till we get the output prediction. A Machine Learning Framework is an interface, library or tool which allows developers to more easily and quickly build models.Some of the most used frameworks are Tensorflow , Keras ,Pytorch etc.., Machine learning is not only used for classification. It can also be used for Regression (continuous data) like prediction of house prices based on its features like sq.yards, number of rooms, area etc..,Detecting and Recognizing text present in the image, Numerical data Analysis and prediction, Speech Recognition in many applications in Business, Marketing, Ads.
Coming back to Neural Networks, It has many layers. Each layer is specific and performs specific tasks. Layers are Input, Hidden, Output. We can add many hidden layers according to requirements based on the deepness of the problem which we are solving. If the problem includes machine learning much more information for classification of the nearly similar type of data, Then it requires deeper (more hidden layers) neural net to learn more patterns, features from an image to make a correct prediction. Input layer takes input pixels of an image and passes it through the hidden layer with some weights and then hidden layer multiplies them (weights and input values) then adds bias along with activation ( All these will be explained further).

combination =weights * inputs + bias.
output = activation(combination).
*Activation may be anything according to our need like Sigmoid, ReLU, Tanh etc.,
Here’s how Exactly a Neural Network works:
1. Information is fed into the input layer which transfers it to the hidden layer
2. The interconnections between the two layers assign weights to each input randomly
3. A bias is added to every input after weights are multiplied with them individually
4. The weighted sum is transferred to the activation function
5. The activation function determines which nodes it should fire for feature extraction
6. The model applies an application function to the output layer to deliver the output
7. Weights are adjusted, and the output is back-propagated to minimize error
The model uses a cost function to reduce the error rate. It updates weights in backpropagation based on the cost function to reach minima (reduce error).
8. The model compares the output with the original result.
9. It repeats the process to improve accuracy.
There are many types of neural networks differentiated based on architectures, hyper parameters to perform various tasks. Convolutional Neural Networks are majorly used for image classification types of problems.
Here, Convolution plays a major role in detecting a given image to give a score required for making predictions. As there is much more to discuss things required for the end-to-end training of a model. This is just a high-level introduction. After getting a trained model it is used for inference purposes running it on the web browser or deploying it in an application based on our requirements. So that just by uploading a picture the end-user can access its features. Now let’s see about types of machine learning.
All we need in today’s life is to automate things to much extent as possible. For that need to be done machines should work for us, To make machine work as we do, it needs to be learned or trained on some data to make itself familiar with the work it has to face in future. This process of making machines learn based on patterns and analytical building with less human intervention to solve problems is known as Machine Learning. There are 5 types of learning, Supervised, Unsupervised, Reinforcement, Semi-Supervised, Transduction.
But let’s see about the first 3 algorithms in this article.
Trending AI Articles:
1. Why Corporate AI projects fail?
2. How AI Will Power the Next Wave of Healthcare Innovation?
Let’s Start with Supervised Learning
It is a part of machine learning which is a part of Artificial Intelligence. We will discuss these parts of Artificial intelligence in our next article, Now let's focus on these types. This type of learning includes giving labeled data for machines to learn along with labels (i.e, for example, if we are training a model to classify cats and dogs we feed the images of dogs in a folder naming dogs and similarly for cats). So that it learns patterns of images along with the ground truth and while making predictions it can use learned patterns to predict exact labels (Either a Dog/Cat).

Moving onto Unsupervised Learning
In this type of machine learning, a model is trained without labeled data as the name suggests they are allowed to act without supervision. So the data given is separated as clusters based on similarities in patterns learned by machines. While predicting an image it finds the closest cluster to with the image patterns match and outputs that class. This type of model helps in grouping similar data from a large set of data. The below figure illustrates unsupervised learning.

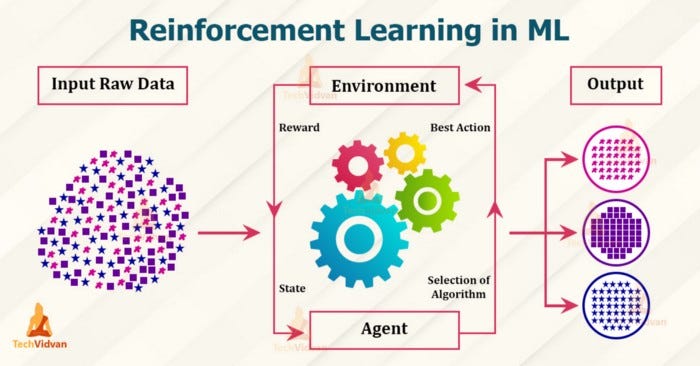
Last but not least, Here comes Reinforcement Learning
This type of learning includes agents, environment. Where agent performs actions in an environment in order to maximize the reward. If the action taken results positive outcome it is rewarded or it is penalized. So this model learns based on the interpreter outcome by reducing the penalties and increasing rewards. This process is repeated until it reaches a correct path with best accuracy for prediction.
So, This is about types of machine learning. Just to reiterate, Mostly used algorithm is supervised machine learning as it helps machines to learn fast and to make accurate predictions. But it is used to make predictions based on trained data only.
An unsupervised learning model is able to find the cluster for an image that is not trained based on the similarity between the trained and test image. Coming to Reinforcement it is similar to the human children as they learn based on outcomes of performing certain things but it takes much more time to learn than other techniques.
All this is fine but the major issue is with data. More data results in a better understanding of images and leads to better accuracy. Sometimes we may not have that much data to train, In that situation comes to our savior Data Augmentation.
In Supervised Machine learning tasks, the prediction accuracy of the model has a huge effect on the data available during training. So it is better to train a supervised learning model with a large amount of data. This is because if the data is more there are chances of learning the patterns in a better fashion forming more neurons in the hidden layers and with more trainable parameters which helps a model for generalizing the output well. So in this way data is directly related to the performance of the model. But including mostly similar kinds of data in huge amounts may lead to overfitting and fewer amounts of data lead to underfitting. These concepts will be discussed further. Now let’s focus on Data Augmentation.
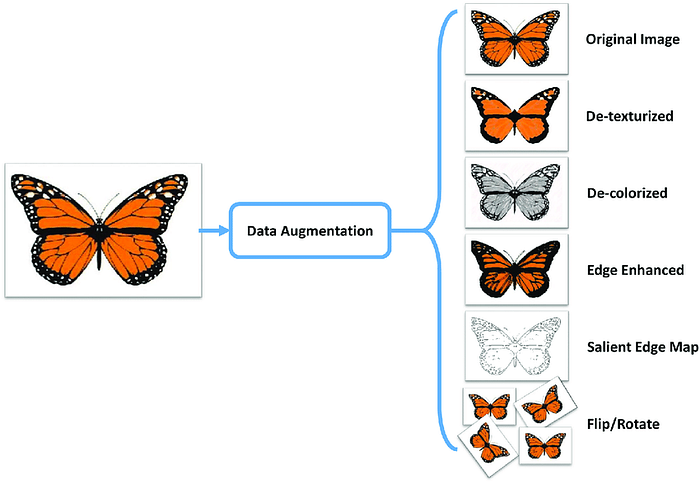
So, For getting a better model we need to train on large datasets and it is possible only if we have large sources of data available of that kind. But in some scenarios where the data (let’s consider for image classification training with image data) is scarce and unable to get more data for training then here comes the savior Data Augmentation, It is a process of enlarging the available dataset to train by manipulating the existing one’s.
Data available can be multiplied by many techniques like rotating with some angle, flipping, zooming, altering the brightness, adding noise etc.., Now we’ll go through some of these techniques to increase the data count.
- Rotating:
The name itself suggests much about it, here we rotate the existing data by a certain angle such that the image is the same but it slightly looks like a skewed one of the original images.

2. Flipping:
This is nothing but a flipped version of the original data point. It may be horizontal or vertical flip or both flip. Have a look at the below figure for better understanding of flipping.

Rotating and Flipping are mostly used techniques for augmenting the data. Even after doing these, the data is insufficient for training we can use some other techniques to increase furthermore.
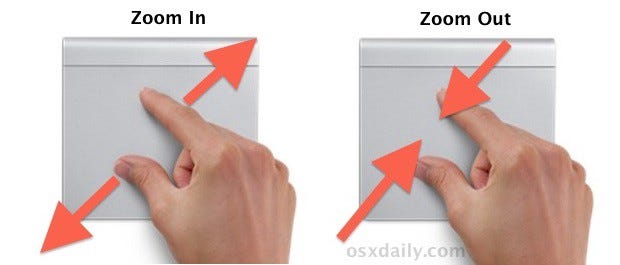
3. Zooming :
It is the process of increasing the pixels by replacing those with neighboring pixels (pixel is the digital representation of an image in RGB each having a value of R,G,B). Zooming can be done in and out as shown in the figure below.
4. Altering Brightness:
Altering Brightness is nothing but altering the intensity of the image by increasing or decreasing the pixel values of a particular image. For example, if we have a value of a pixel as 15 and another with 30 then here 15 and 30 are intensities of it, and the image with pixel value 30 is more bright. So brightness is defined intensity and it is a visual perception of an image.

5. Addition of Noise:
Adding noise to images allows you to test the robustness and performance of an algorithm in the presence of known amounts of noise. So, Adding noise data in our training set makes it robust while predicting such real-time images as they may have some noise. It helps in both ways to increase the data count as well as to make the model robust, Anyways tending towards the final result to increase the accuracy of our model's prediction.
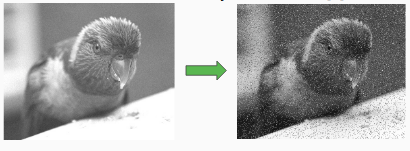
There are even more techniques like cropping, shear, shrinking etc.., but these are mostly used ones to augment the data. There are many libraries out there for manipulating the images by preprocessing it and for augmenting data but open cv is one of the mostly used one as it makes the task in more efficient and beautiful manner. All the documentation regarding image handling techniques is available in it. Wanna have a look, here it is https://docs.opencv.org/4.5.2/d9/df8/tutorial_root.html
Not only collecting much data but it is much important to make sure that data is neat and clean. To do so we have to make our data go through some preprocessing steps. Let’s have a look into it.
Coming to preprocessing, It helps to make data sufficiently clean for a model to learn all the patterns and edges required to make a correct prediction. So it is a must while passing the data to Neural Network for training and testing. Some of the most common used preprocessing techniques for image classification are:
- Image Resizing :
It is done to an original image to change its size, Resizing is necessary before training because some of the images because of variations in the data used while training a model i.e, data collected from online sources, taken from a mobile etc.., may vary in the sizes. So, To form a base size for all the images we particularly resize all the images. Here while resizing we mostly convert images to 224*224, where it detects all the shapes, patterns required to be learned making computations less complex ( as pixel size decreases computational efficiency decreases). But if we use even less size the model may not behave well.

2. Removing Noise :
It is a process of removing noise from the image to make learning better. We use this preprocessing function to smoothen the image to reduce unwanted noise. This is majorly done using Gaussian blur. It is a method to reduce the noise by smoothing the image. By doing so the visual effect is in such a way that the image is seen through a translucent screen

3. Binarization :
It is nothing but converting an RGB image into the Black and White image. This is done so to avoid more learning at the colored patterns where the pixels values are more and the model tends to give more weight. So, this preprocessing step helps to make all the pixels separated into white and Black based on the threshold. The important thing to notice here is setting the best threshold.
The white pixel value is 255 and that of Black is 0.
With our threshold, let's say 127 less than 127 value of the pixel is considered as white and the remaining ones as Black. This will be most helpful in-text detection and recognition-type problems.
But there is a stumbling block here, if the image is subjected to a lighting condition it becomes difficult to set the common threshold for all the pixels of that particular image and in that case, this step may not be useful. You can have a look at such a case in the below figure.

There are many methods out there for setting these thresholds in this preprocessing step. But the most used one is OTSU’s threshold as it considers lighting, sharpness, contrast, etc., of a particular image to fix a better threshold.
We also have an adaptive threshold where instead of considering a single threshold for the whole image, It takes a different one for each pixel based on characteristics of neighboring pixels. All these can be thresholding are predefined and can be used directly with huge computer vision libraries like cv2 and also image libraries like PIL.
4. Noise Removal :
As we know noise plays a major role in hiding the important information in an image and makes the learning process difficult while detecting patterns and edges present in it. So removing that noise is the primary objective of this preprocessing step. This is done by smoothening the image and removing the small dots/patches which may have high intensity than the rest of the image. Noise removal is performed for both colored and binary images.
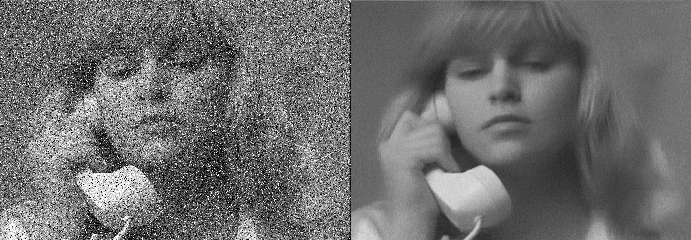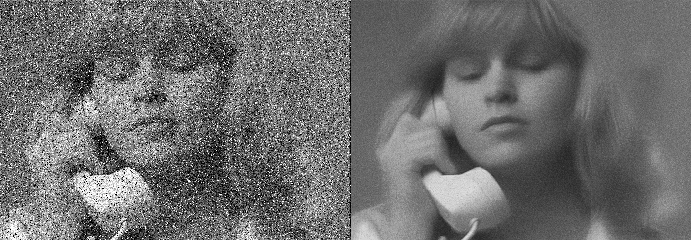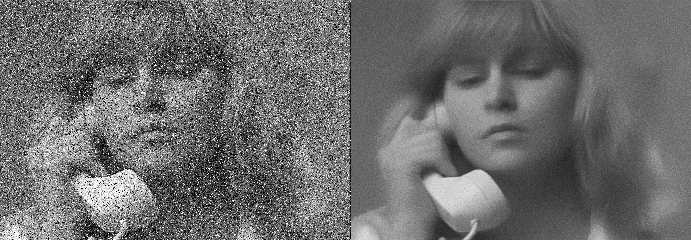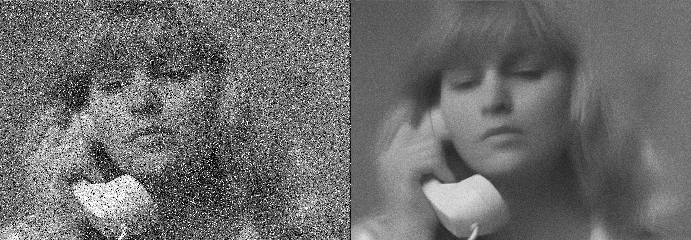
These are some of the most used preprocessing techniques for image classification. After all, this is done then that image is passed into a neural network for training, It goes through forwarding propagation, Where convolution is the major part. So let’s have a look into convolutions.
Before going into convolutions let's first see how the need of convolutions arises. For a machine learning model to make predictions it has to learn all the edges, shapes etc., present in an image that we feed while training. So it has to pass each and every pixel of the image to derive an approximate weight based on that particular pixel. Convolution helps to make this happen. FYI, In digital imaging, a pixel(or picture element) is the smallest item of information in an image. Pixels are arranged in a 2-dimensional grid, represented using squares. No more waiting… let's go on to Convolutions!!
Convolution is the simple application of a filter to an input that results in activation. Repeated application of the same filter to an input results in a map of activation called a feature map, indicating the locations and strength of a detected feature in input, such as an image. A Filter or Kernel with some weights convoluted with every pixel of an image.
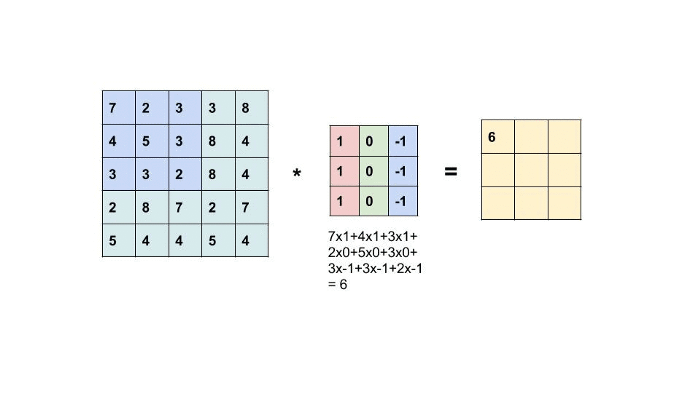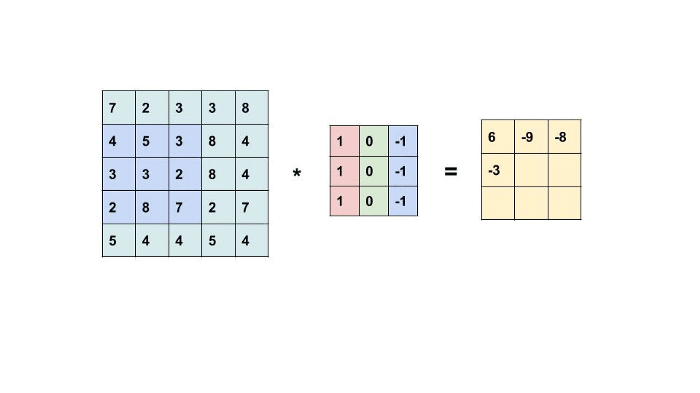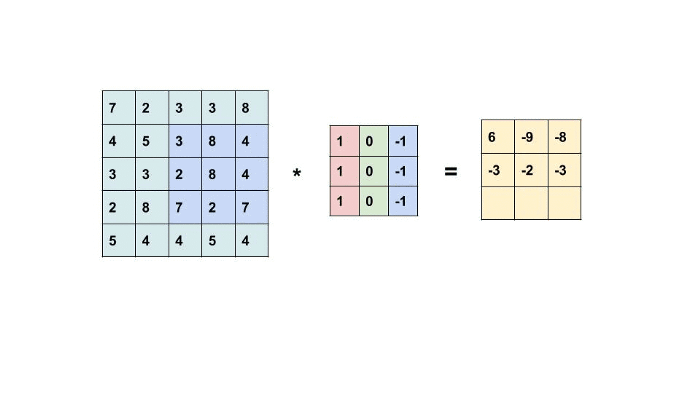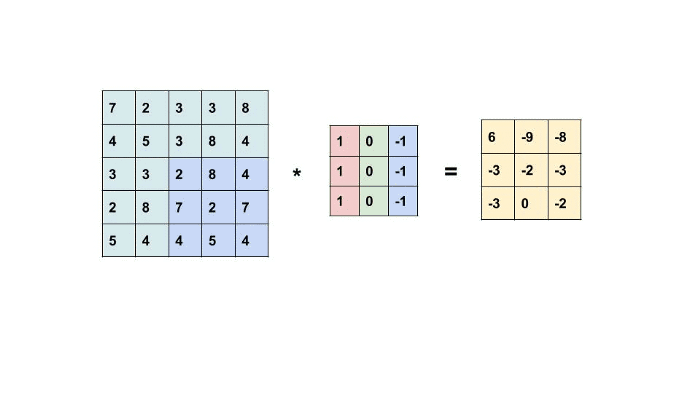
From fig a, the kernel is applied to the input image to generate an output feature map that resembles input features like edges, patterns, etc., but decreases its dimensions to make further computations easy. For example, the Input image is 4*4 and Kernel is 2*2, Output is 3*3. So here we get the reduced dimension of an input covering crucial features taken from the image.
The kernels are designed in such a way depending on output requirements. Detecting particular edges or patterns like horizontal, vertical requires such kernels to be convoluted with an image. Output is nothing but a dot product of input image and kernel (convolution). Shown in the below figure.
One more thing is that your output can be changed with some new techniques. If you want to get output the same as the input dimension then Padding is used. For even more decreasing the dimensions of it we use a higher stride value. FYI, Stride is a parameter of the neural network’s filter that modifies the amount of movement over the image. Let's see about Padding and Strides.
Hope you got some idea about convolutions, Now we will move onto some details of what are padding and stride and why are they used.
So, In Convolutions, we get the shrunk version of an input image after convolving with the filter or kernel of weights. So get a reduced number of pixels for an image after convolution and by repeating this procedure, after some operations of convolutions over multiple layers we may have a very number of pixels which may define much about the input image to predict accordingly. If we want to maintain the image pixel the same as the input while performing convolutions then we add padding to an input to prevent shrinking.
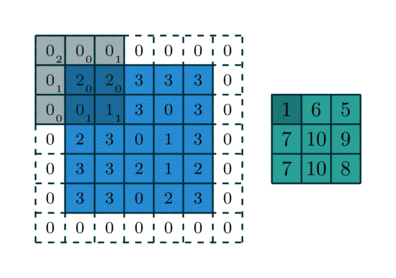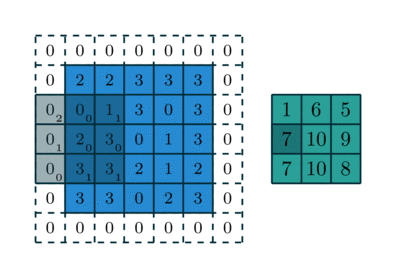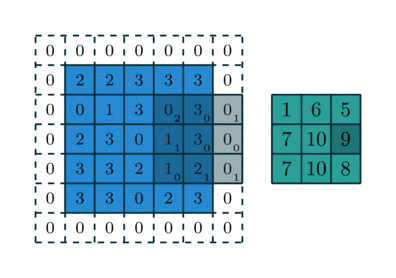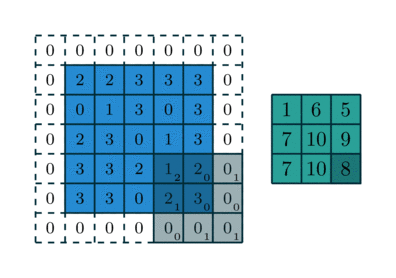
By Padding, we are not only preserving the input shape after performing multiple convolutions but also concentrating more on the edges information of an image rather than only concentrating on the center of the image multiple times while convolution,which helps in better prediction. Here in the above image, you can see it is padded with one layer of 0’s on all sides so we get 2 more rows, columns. For example, if the image is 5*5 it becomes 7*7 after padding.
So padding makes convolutions with same shape as input. Let’s represent it in a mathematical formula for better understanding and memorizing.
n = number of pixels of an input image
p= padding number
f = filter size
from these (n*n) + (p*p) convolution (f*f) gives → (n+2p-f+1) * (n+2p-f+1)
Considering an example to justify the above formula, n=3, p=1, f=3
n+2p-f+1 →3 . So we preserved input shape. One more important thing is that we mostly use odd sized filters like 3,5…. because to maintain correct padding ratio and conserving the central position to make them symmetric along the origin and it is a good property.
Coming to Stride, It is nothing but steps taken by the filter over an image. If the stride is 2 it moves by 2 pixels right/ bottom after every convolution. Which makes lesser convolutions and results in reduced dimension of output image. It is clearly shown in the below strided convolution figure
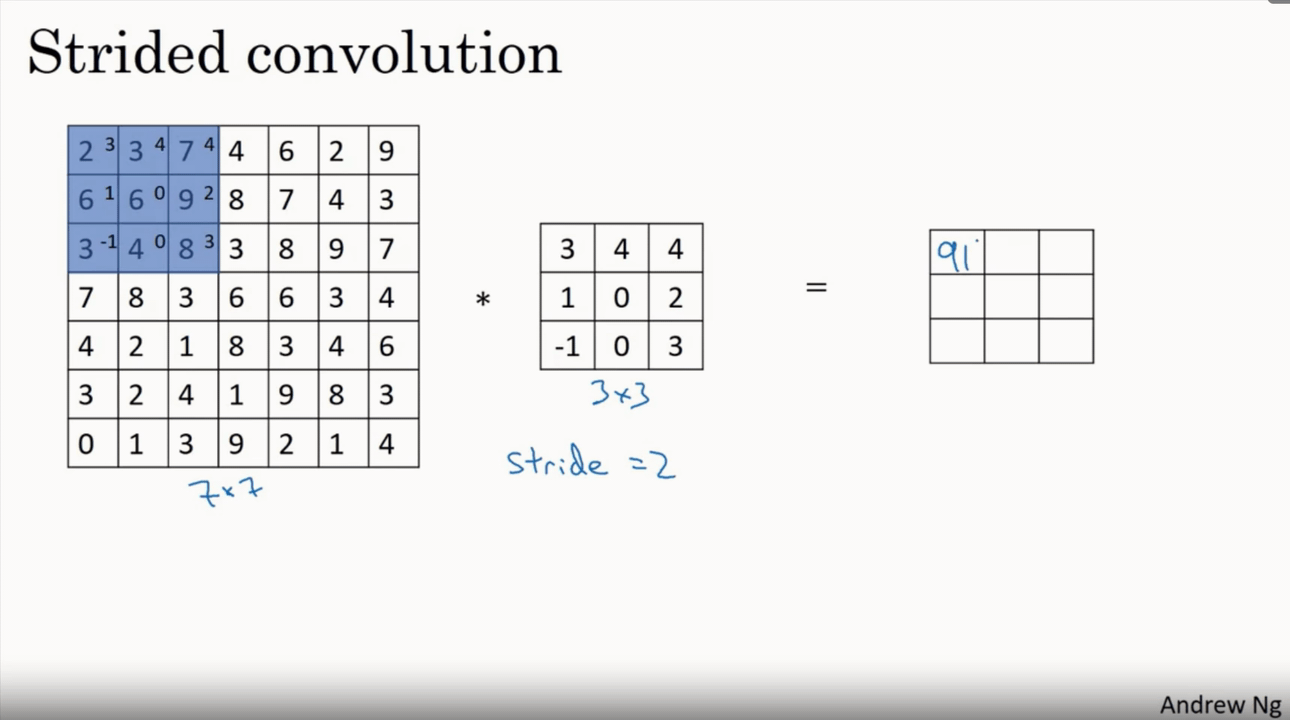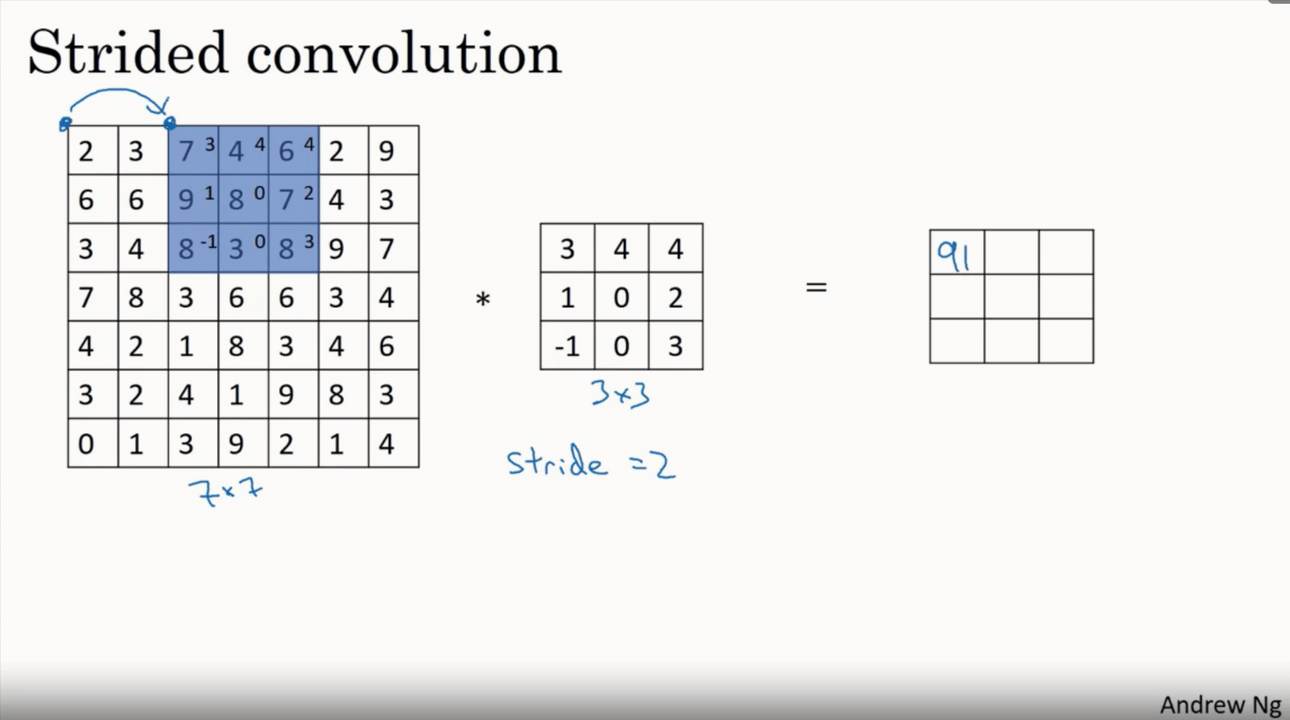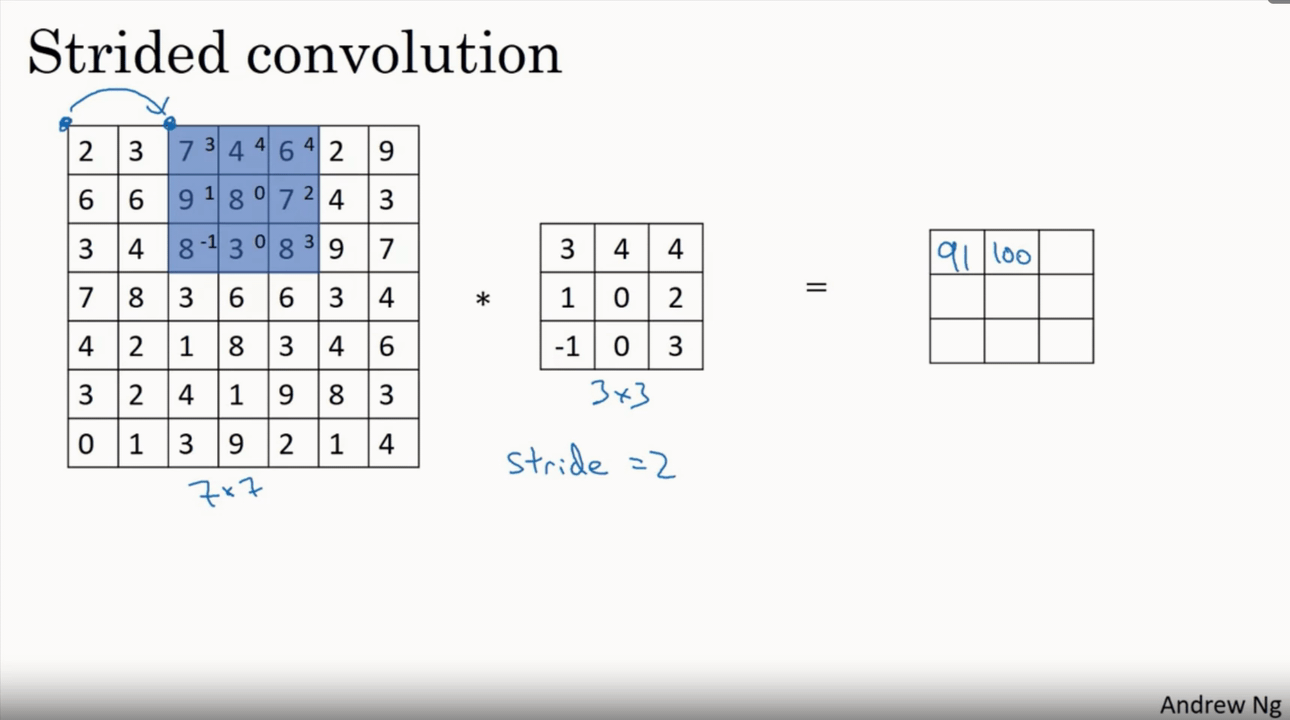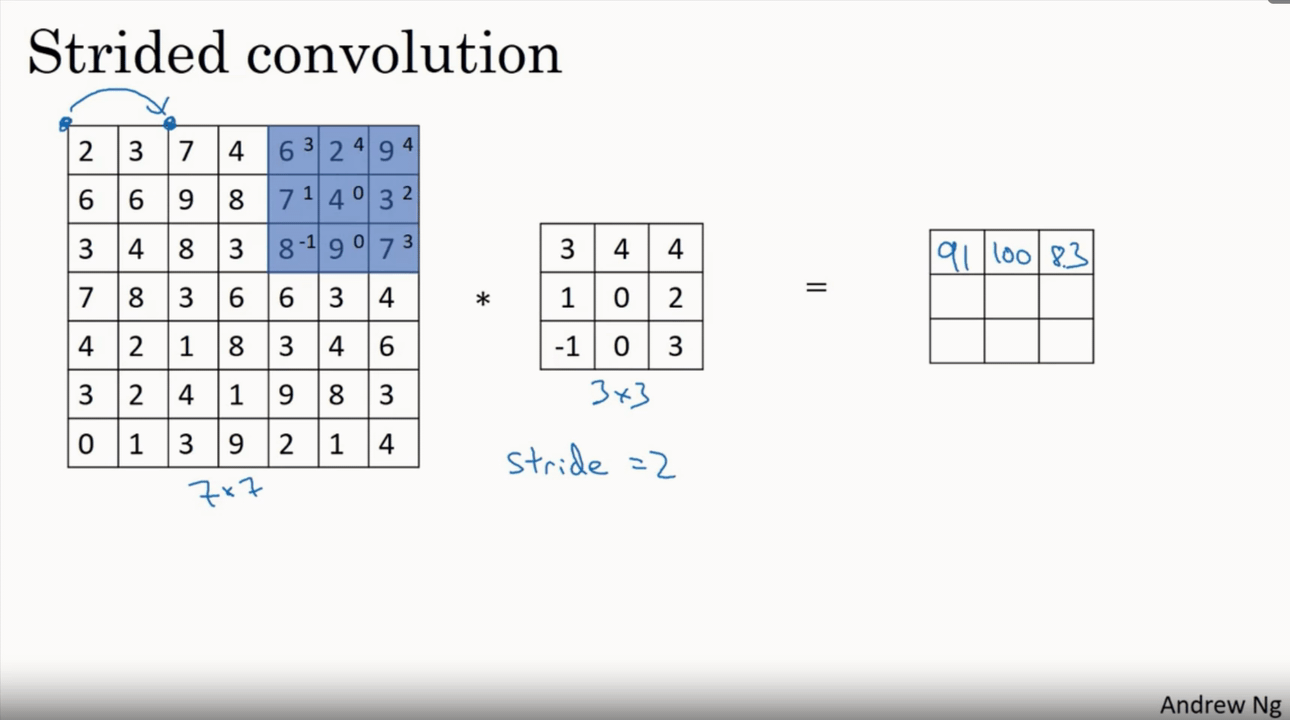
If the stride is increased the output size will be reduced but it must be preferred less than or equal to filter size to cover all pixels.So on overall stride is for reducing the features or size of an image and padding is for increasing or maintaining the same size of an input image.Formula used to calculate size of output image with different stride is
Considering n,f,p same as in padding case lets denote stride by s
output image size → (n+2p-f)/s +1 * (n+2p-f)/s +1
Convolutions can be done with multiple filter channels on same image and then added later on to derive single output feature map.That’s all for padding and stride. All the feature maps(matrix of of values representing an image)generated through convoultions are used to find a value of neuron in the next layer and activation is applied to it. Ooo!!!!, Got a new term again.
It’s fine, lets know about Activation functions.
In any Neural Network activation plays a crucial role. As it helps in making decisions easier by making the complex value to predictable one. This can be used in image classification,object detection , language transformation etc..,
without these computations are complex to handle. It helps in increasing the ability of a network to make predictions by shooting up the speed to converge and make decisions based on that output.
Activation function defines the output of input or set of inputs or in other terms defines node of the output of node that is given in inputs. They basically decide to deactivate neurons or activate them to get the desired output. It also performs a nonlinear transformation on the input to get better results on a complex neural network.
The neuron is basically is a weighted average of input, then this sum is passed through an activation function to get an output.
Y = ∑ (weights*input + bias)
Here Y can be anything for a neuron between range -infinity to +infinity. So, we have to bound our output to get the desired prediction or generalized results.
Y = Activation function(∑ (weights*input + bias))
So, we pass that neuron to activation function to bound output values within a certain range.
Why do we need Activation Functions?
Without activation function, weight and bias would only have a linear transformation, or neural network is just a linear regression model, a linear equation is polynomial of one degree only which is simple to solve but limited in terms of ability to solve complex problems or higher degree polynomials.
But opposite to that, the addition of activation function to neural network executes the non-linear transformation to input and make it capable to solve complex problems such as language translations and image classifications.
In addition to that, Activation functions are differentiable due to which they can easily implement back propagations, optimized strategy while performing back propagations to measure gradient loss functions in the neural networks.For doing these tasks there are many activations with us. So, Let’s look into types of Activation Functions.
Types of Activation Functions
- Binary Step Activation Function:
This is a basic activation function used to bound the output between 2 classes. As it considers a threshold value and makes decisions based on that value. Threshold may vary according to our requirement.
f(x) = 1 if x > 0 else 0 if x < 0
2. Linear Activation Function :
It is a simple straight line activation function where output is directly proportional to the weighted sum of the inputs. There is nothing much about it. As it is the linear combination of weights and inputs.
So, Its equation is Y = m*Z
3. ReLU ( Rectified Linear Unit) :
It is most widely used Activation Function, It outputs values ranging from 0 to infinity , All the negative values are converted to zero. Its conversion rate is also fast. But the only problem is completely neglecting the negative values.
y = max(0, x). x is the input.
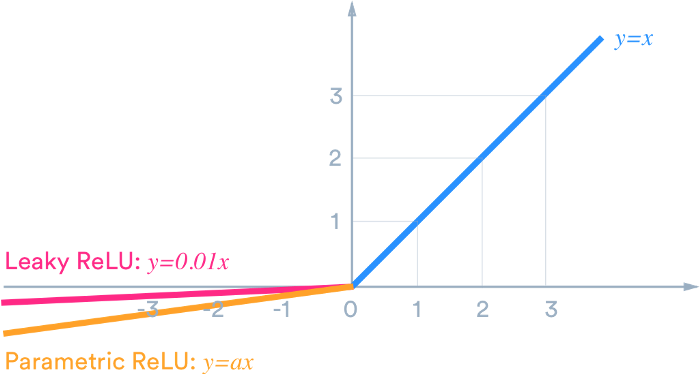
Leaky ReLU function instead of ReLU to avoid this unfitting, in Leaky ReLU range is expanded which enhances the performance.
4. Leaky ReLU:
We needed the Leaky ReLU activation function to solve the ‘Dying ReLU’ problem, as discussed in ReLU, we observe that all the negative input values turn into zero very quickly and in the case of Leaky ReLU we do not make all negative inputs to zero but to a value near to zero which solves the major issue of ReLU activation function.
5. Sigmoid Activation Function:
It is one of the mostly used activation function as it does tasks with great efficiency. It used probabilistic approach to make the predictions between 0 and 1 and then decide the output based on the max probability. So, if a class has more probability than all other classes then it is the predicted output.
Along with advantages there is also a drawback with vanishing gradient problem which occurs because of converting large value between 0 to 1, which doesn’t give expected probabilistic value and due to this there will be mismatch in the predicted and original one. So ReLU is used in this cases.
Its Equation is f(x) = 1/(1+e(-x) )
6. Hyperbolic Tangent Activation Function :
This activation function is slightly better than the sigmoid function, like the sigmoid function it is also used to predict or to differentiate between two classes but it maps the negative input into negative quantity only and ranges in between -1 to 1.
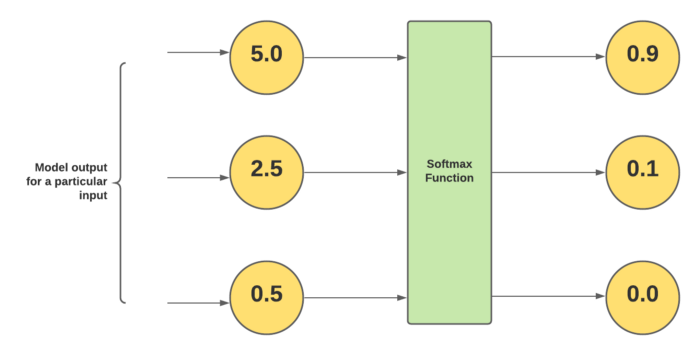
7. Softmax Activation Function:
It is used in last layer of the neural network to make prediction. It works similar to sigmoid function and predicts the probabilistic value for an input based on product of weights and inputs and sum with bias.
The activation functions are those significant functions that perform a non-linear transformation to the input and making it proficient to understand and executes more complex tasks. All the above discussed activation functions are used for same purposed but in different conditions.
So, By this we’ve covered the journey of Machine Learning from collection of data to Forward Propagation. Here in forward propagation after application of Activation we get a predicted output for a given image,But there may be difference in input and predicted value. To avoid this loss we need to minimize the loss function and optimize in order to reach maximum accuracy. That will the topic for coming article.
You are just a second away from hitting a clap(like), Which makes me motivated to write more such stories :)
Thank You!!!!! For reading my article.. Do Follow and Share it for Needful.
Don’t forget to give us your 👏 !




